Seguramente alguna vez su gerente les ha consultado si la cantidad de procesadores o la velocidad de los discos es adecuada para garantizar que el sistema permanezca estable. Ante esta pregunta uno puede simplemente tener confianza y contestar que todo va a funcionar bien o uno puede ser mas profesional y realizar un CP y saber con exactitud en donde estará el punto de quiebre, es decir no solo contestar si el HW soporta la carga actual sino tambien, teniendo la proyección de crecimiento transacccional anual, saber hasta donde nos alcanza nuestro HW y preveer con tiempo la compra o upgrade de HW.
Ahora vayamos directamente a ver como se modela un subsistema de cpu y un subsistema de i/o. Para realizar CP mas sofisticado es necesario tener cierto conocimiento de Teoria de Colas (función Erlang C, Notación de Kendall, etc). En esta nota simplemente alcanza con un poco de criterio. En el gráfico A) se modela el subsistema de CPU. Este consta de una sola cola y N servers (cpu's). Esto quiere decir que cada petición puede ser atendida arbitrariamente por cualquier server o cpu y se van encolando cuando todas las cpu estan ocupadas (runqueue en terminos de SO). En el gráfico B) se modela el subsistema de I/O donde tenemos una cola por server o device. En este caso cada petición debe ser atendida por un device determinado.
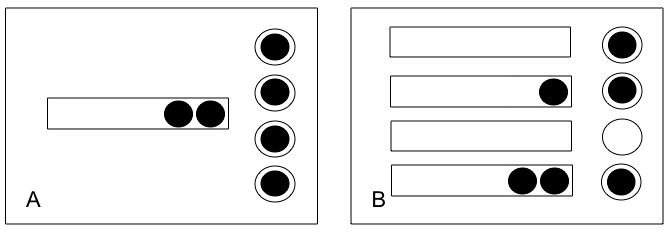
Los dos modelos mencionados se representan infinidad de veces en la vida cotidiana, cuando vamos al banco, cuando estamos esperando en la estación de peaje, cuando esperamos para abordar un vuelo, cuando vamos a hacer nuestro pedido en un restaurant de comida rapida, etc.
Ahora vamos a definir las variables que necesitamos usar para realizar el CP:
Uc= User Calls
trx= transacción
λ= tasa de arribo (ej: trx/ms ó Uc/ms)
St= Tiempo de Servicio (ej: s/trx ó s/Uc)
Qt= Tiempo de Espera o Tiempo de espera (ej: s/trx)
Rt= Tiempo de Respuesta (ej: s/trx)
Q= Encolamiento (ej: Nro de trx's)
U= porcentaje de carga (porcentaje de utlización del recurso)
M= nro de servers (cantidad de CPU's o cantidad de IO devices)
y las formulas:
Rt = St + Qt
U = St * λ / M
Q = λ * Qt
Rt(cpu) = St / (1-U^M)
Rt(io) = St / (1-U)
El objetivo es conseguir graficar el tiempo de respuesta vs tasa de arribo. El gráfico debería ser tipo exponencial con una curvatura o punto de quiebre que muestre a que tasa de arribo (eje X) se produce dicho quiebre.

Voy a explicar un poco mas en detalle que significa cada cosa:
1) λ (Tasa de Arribo): Esta se puede definir con métricas de Oracle tales como: Uc/s o Trs/s, o usar una métrica funcional, por ejemplo: carga de ordenes de compra por minuto o por hora.
2) M (Cantidad de CPU´s y I/O Devices): Es la cantidad de cpu's o I/O Devices. Para obtener este valor podemos usar utilitarios de SO y/o consultar vistas de Oracle.
3) U (Porcentaje de Carga): Es el porcentaje de carga de cpu o I/O. Esto se puede obtener usando utilitarios de SO como sar, iostat.
4) St (Tiempo de servicio): Es el tiempo en el que la petición esta siendo atendida por la cpu o por el dispositivo de i/o.
5) Qt (Tiempo de Espera en la Cola): Es el tiempo que una petición tiene que esperar en la cola porque los servers estan ocupados.
6) Q (Largo de la Cola): Es la cantidad de peticiones encoladas (esperando ser atendidas)
7) Rt (Tiempo de respuesta): El tiempo de respuesta es la suma de St (service time) y Qt (tiempo de espera o encolado). Una petición o esta esperando o esta siendo atendido.
En este punto, donde creo haber definido todo, les voy a mostrar un ejemplo:
Ejemplo (Capacity Planning de CPU)
Supongamos nos piden estimar el impacto que se producirá si se incrementan los usuarios de una aplicación X en un 20%. Lo que se quiere determinar es si se necesitará agregar mas procesadores o con lo que hay es suficiente para soportar la carga adicional.
Lo primero que tenemos que hacer es recolectar información en un periodo representativo. Cuanto mas datos recolectemos mas precisa será nuestro CP, luego debemos caracterizar la carga, esto significa definir si vamos a usar valores promedio, maximos, que vamos a usar como tasa de arribo, etc. En el ejemplo yo voy a tomar valores picos en un intervalo de maxima carga y como tasa de arribo usaré Trx/s.
λ= 20 trx/s (20 transacciones por segundo, se puede obtener desde statspack o AWR)
U= 0,40 (40% de utilización de cpu, esto se puede recolectar con sar -u)
M= 8 (hay 8 procedores, se obtiene desde el parametro de la base: cpu_count)
Ya tengo los 3 parametros escenciales, ahora solo tengo que aplicar las formulas y graficar:
U = St * λ / M, depejando para obtener St,
St = U * M / λ = 0.40 * 8 / 20 = 0,16 s/trx
Ahora que tenemos St podemos aplicar la formula para cpu:
Rt(cpu) = St / (1-U^M) = 0,16 / (1-0.40^8) = 0,16 s/trx
Como se observa el tiempo de respuesta es igual al tiempo de servicio. Esto se da porque el sistema esta holgado en cpu para la carga actual y no se producen encolamientos, es decir hay que esperar para ser atendido por las cpu's. Ahora lo que voy a hacer es una tabla en excel para proyectar el crecimiento y graficar la curva de manera de ver donde se produce el quiebre.

Vemos que el punto de quiebre esta alrededor del 30-35% (>), pensemos además que estamos partiendo de un workload pico y por lo tanto podemos pensar que la mayoria del tiempo va a estar bastante por debajo. De acuerdo al CP podemos asegurar que el sistema amortiguará bien la carga adicional del 20%, comenzando a degradarse rapidamente a partir del 25%.
Ejemplo 2 (Capacity Planning de I/O)
Como analizamos en el ejemplo 1, no tendriamos mayores problemas con la cpu al incrementar en un 30% la carga. Ahora veamos que ocurre con los discos.
λ= 5Mb/ms (5 Mb de transferencia por milisegundo, se puede obtener con sar -d o iostat)
U= 0,60 (60% de utilización de i/o)
M= 50 (hay 50 devices)
St = U * M / λ = 50 * 0.60 / 5 = 6 ms/Mb
Reemplazando en la formula de i/o:
Rt(io) = St / (1-U) = 6 / (1-0.60) = 15ms/Mb

Como se ve en el gráfico, el sistema podría soportar hasta un 50% (7.5Mb/ms) de crecimiento, una vez que llega al 60% de destabiliza.
Como resumen podemos inferir que nuestro Hardware esta bien a nivel cpu no tanto a nivel i/o ya que no escalará a largo plazo.
En esta nota mi idea fue mostrar como realizar un capacity planning de cpu y i/o en forma sencilla. Con este metodo tendremos una buena estimación de como escalará nuestro HW. De acuerdo a cada caso existen otros enfoque para modelar tales como el metodo basado en ratios, Teoria de Colas y metodo de regresión lineal.
Lo mas importante para obtener estimaciones precisas es obtener una buena muestra, que sea representativa sumado a una buena caracterización de la carga de trabajo a evaluar. Cuanto mas información hayamos recolectado mejor será nuestro pronóstico.
Usando esta metodologia se puede realizar simulaciones y proyectar a futuro, por ejemplo: que pasaría si agregamos o sacamos cpu's, como impacta el agregado de dispositivos de i/o mas rapidos, con mayor throughput y menor latencia, cuantos usuarios se podrian agregar para que operen con la aplicación sin poner en riesgo la estabilidad del sistema, etc.
Para los que le interesen temas de Capacity Planning en Oracle les recomiendo:
"Forecasting Oracle Performance". Este libro escrito por Craig Shallahamer, un verdadero gurú en el tema, me pareció excelente y lo usé como referencia para escribir la nota.

.JPG)